Trustworthy AI Isn’t a Principle, It’s a System: Insights from the Cambridge Wireless Trustworthy AI Event
This time last week I was on my way home from “Trustworthy AI: From Principles to Critical Applications”. An event hosted by Cambridge Wireless and Anglia Ruskin University, at its new Advanced Computing Research Centre.
I went in as a Quality Engineer, curious about where the industry is heading. I came out with pages of notes, a few moments that genuinely shifted my thinking, and more questions than answers. This outcome is, for me, always a good sign.
Here is what I took away.
The uncomfortable truth
Linda Oraegbunam, from the UK Civil Service opened with a set of statistics that set the tone for the day:
- 87% of CIOs report AI agents already embedded in workflows
- Only 33% have mature governance processes to manage them
- 75% lack real-time visibility of those agents in production
- 80% have experienced risky, unexpected agent behaviour
These numbers aren’t shocking, yet unsurprising in equal measure. And that’s the problem.
Do not confuse accuracy and performance with reliability
This one hit hard early on. Professor Shareeful Islam from ARU opened with a deceptively simple challenge to something most of us take for granted.
A model can be 99% accurate and still:
- Systematically fail specific groups (bias).
- Memorise training data in ways that expose individuals (privacy).
- Produce harmful outputs with high confidence (hallucination)
- Treat similar cases differently depending on context (fairness)
The statement that accuracy does not equal reliability reframed the question entirely. Accuracy tells you the model is performing. It doesn’t tell you the model is trustworthy. Those are different assessments requiring different test strategies, and that distinction should change how we design our test coverage.
Professor Islam mapped this across six pillars: privacy, fairness, security, robustness, safety, and explainability. He then tied each pillar to a phase of the development pipeline.
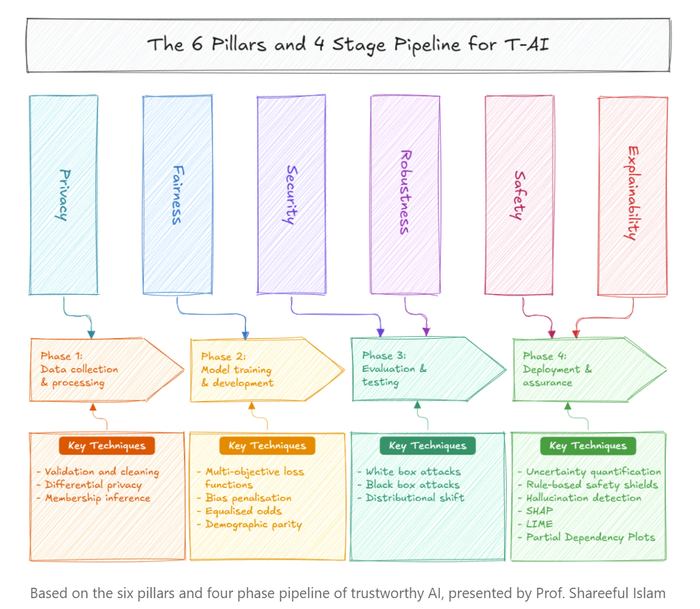
For the QE community, the explainability techniques he highlighted are worth knowing:
- SHAP: feature importance scoring
- LIME: local prediction explanations
- Partial dependence plots: how each input feature affects the output across its full range
The insight that changes the mindset
Pauline Harrison of KernEthik gave what was, for me, the most practically impactful talk of the day.
She introduced the concept of the non-use case, and I haven’t stopped thinking about it since.
During the traditional SDLC, the focus is on defining what a system should do. Use cases. User stories. Requirements. As Quality and Test Engineers, we then build test cases to validate and verify those requirements. As part of this, we identify edge cases. We excel at asking, “But what if someone used the system in this way?”
But what about explicitly defining what the system must not do?
In traditional software, this is underrepresented. In AI, it is a critical gap. The EU AI Act's Article 5 directly references it, which provides regulatory weight. It is no longer just good practice; it is essential.
The shift this created in my thinking:
Shift left
Non-use cases shouldn’t arrive at testing. Embed them at the front end of the development lifecycle, in requirements, architecture decisions, and governance gates, before producing a line of code.
Shift right
Once in production, those same non-use cases become the benchmark for continuous observation:
- Watching for drift.
- Watching for boundaries being pushed.
- Watching for the system doing something it was never supposed to do.
This is where I think QE has a real and underutilised role. QE's role extends beyond simply verifying what was built. It should define, from day one, what must never be, and then watch for it continuously in production.
Three Amigos of AI Governance
Pauline also structured this within what she called the Three Amigos of AI Governance:
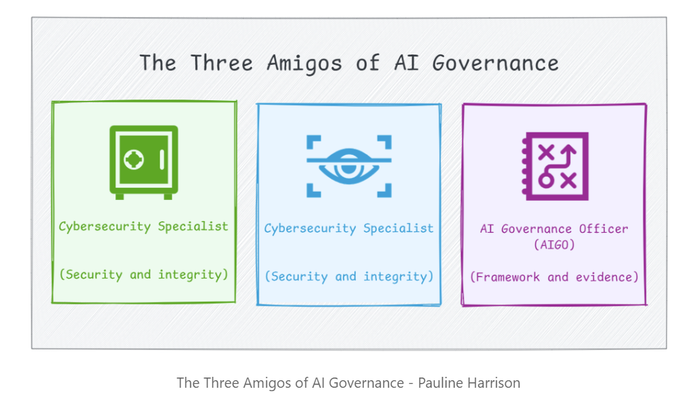
Three independent but coordinated roles. The AIGO acts as the conductor, whilst the baton is the policies, procedures, and evidence trail.
This is where I think the QE community needs to have a conversation about where we sit.
We’re not a fourth Amigo. But we can play multiple key roles within the orchestra.
Depending on the specialism, a Quality Engineer can meaningfully support activities under each of the three roles:
- Alongside the DPO: designing test cases to validate data handling, privacy controls, and inference-attack resistance
- Alongside the Cybersecurity Specialist: contributing to adversarial testing, red teaming, and model integrity verification
- Alongside the AIGO: building and maintaining the evidence trail, the use case and non-use case framework, and the test artefacts that make compliance demonstrable rather than theoretical
The AIGO conducts. But the orchestra needs players who can operate within their sections and have a strong understanding of the others. That’s a role QE is well placed to fill, if we position ourselves for it.
The auditor's mindset
Alongside the Three Amigos, Pauline introduced something she called the auditor’s mindset. For anyone in QE, this should feel like home territory.
The auditor’s mindset is simple:
“Show me.”
Not “tell me about your governance.” Not “point me to your policy document.”
Show me:
- The documented risk assessment
- The test logs
- Who approved this system for deployment, and when
- The training records of the person overseeing it
This is evidence-based quality assurance applied to AI governance. It’s the same discipline we apply when we sign off on a test cycle or close a defect. The difference is that the stakes are now regulatory, not just operational. An organisation that can’t answer those four questions under scrutiny has a governance system that exists only on paper.
For QEs, this is familiar ground. We know how to build evidence trails. We know what “documented and traceable” looks like. That skill set is directly transferable, and in the context of AI compliance, genuinely valuable.
For further reading
Pauline referenced a comprehensive survey on red teaming from the University of Melbourne : Against The Achilles’ Heel: A Survey on Red Teaming for Generative Models. It covers over 120 papers on attack strategies, defences, and benchmarks for generative AI. It’s next on my reading list and looks genuinely useful for anyone working in AI assurance.
Her closing line:
“Trustworthy AI is not a philosophy. It is a management system.”
That’s the line I’ll be quoting for a while.
Agentic AI: mind the governance gap
Felicia Omoediale-Samuel from Sky brought the threat landscape into sharp focus, specifically around multi-agent AI systems in cyber defence and critical infrastructure.
What struck me most was her autonomy spectrum, five stages transitioning from low to high:
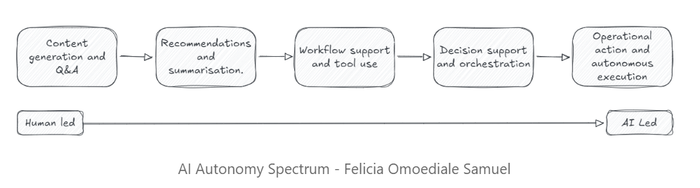
Most organisations deploying agents today are somewhere between stages 2 and 4. But the governance models they’re using, if they have them at all, were likely designed for stage 1.
Felicia walked through a scenario involving a compromised multi-agent cyber defence system. The scenario demonstrated how an adversarial attack could propagate through six sequential agents, from threat intelligence, through triage and recommendation, to the production of a misleading audit trail. Each agent is a potential point of failure. Each handoff is a potential attack surface.
Five critical questions to ask about every agent
Her five questions to ask about every agent have gone straight into my working notes:
- What can it see?
- What can it do?
- What tools can it call?
- When must a human approve?
- How do we stop it or reverse it?
Simple. But how many teams deploying agents today could answer all five?
Her resilience model felt immediately familiar to me from my manufacturing background:
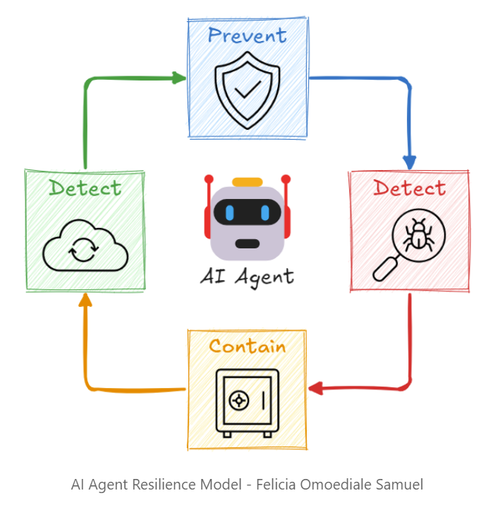
In continuous manufacturing, when problems occur, action is taken to isolate the affected product, determine the root cause, and then put in place and confirm solutions through methodologies such as 8D Reporting and the PDCA cycle. The logic is near identical.
This reinforced a belief I have held for some time. It underscored how closely disciplines from automotive and FMCG manufacturing, two highly regulated industries, align with what trustworthy AI governance is trying to build:
- Embedded quality
- Clear ownership
- Continuous monitoring
- Structured improvement.
The Toyota Motor Corporation solved a structurally similar challenge decades ago with the Toyota Production System. The gap isn’t knowledge, it is application. We haven’t yet carried those lessons consistently into AI.
That feels like an opportunity worth pursuing.
The philosophical anchor
Professor Deeph Chana from Imperial College London offered the most thought-provoking moment of the day. Less about frameworks, more about foundations.
He described every AI system as a key. That key can open remarkable doors: drug discovery, smarter infrastructure, better healthcare. But the same key opens the other door too.
“No result is innocent.”
He also made an observation I think is genuinely important. The gap between discovery and deployment has essentially vanished. The old model, where academia invents and then industry and government figure out governance before deployment, no longer exists. The timeline has collapsed.
Which means the responsibility for considering both doors falls on those of us building and deploying these systems now, including those in testing and quality.
I found myself connecting this to Pauline’s non-use case framework. Defining what a system must not do isn’t just a compliance exercise. It’s the QE community’s contribution to ensuring the right door opens.
Applying safety principles to ethics
Dr Catherine Menon from the University of Hertfordshire made a distinction I haven’t fully worked through yet, but it’s stuck with me.
The difference between ensure and assure:
- Ensure: how likely is something to happen?
- Assure: how much can you convince others of the likelihood?
One is a probability calculation. The other is an evidence-based argument.
She then applied HAZOP (Hazard and Operability Study), a technique from safety-critical engineering, to ethical concerns. She identified ethical hazards including loss of human autonomy, erosion of confidence, and lack of privacy in the same way you would identify safety hazards in a chemical plant.
The idea that you can apply the same methodology to ethics, and that ethics like safety is amenable to rigour, opens up something interesting for how we approach AI test design. Still thinking about where it leads.
So, where now?
I don’t have tidy conclusions from a day like this. More a set of questions I’m now thinking about differently:
- How do we make non-use cases a first-class citizen in AI requirements processes?
- What does continuous production monitoring look like when the “product” is an AI agent making autonomous decisions?
- How do we build the evidence trail that transforms risk assessment into genuine assurance?
- How does the QE discipline position itself within the Three Amigos governance model? Not as a fourth Amigo, but as a cross-cutting capability that supports all three depending on specialism?
If you’re working in AI quality, testing, or governance and this resonates, I would be keen to hear your perspective. These are questions the QE community should be addressing collectively.
A huge thank you to Cambridge Wireless, Anglia Ruskin University, and all the speakers for a day that gave me a lot to think about.