By: Josip Rozman Consultant, Plextek Science fiction has long played with the idea of a creative, and mostly benevolent AI which would be able to produce innovative works of literature and art of the highest quality. The hype is partially to blame for our extremely high expectations of said models, and to a degree of disappointment when our expectations are not completely met. There are currently two big areas of research for generative models: natural language and image (video).
Regarding natural language models the trend started with large language models such as the GPT family producing text sequences. Some of the notable examples include AI powered chat bots, an interactive Dungeons and Dragons prompt, and code writing AI (hence I am writing blogs now).
The second trend is the AI image generation and the topic I would like to focus a bit more on in this blog. The trend started with models such as Generative Adversarial Networks (GAN-s) and Variational Autoencoders (VAE-s) which produced some high-quality images, but they were limited in what they could achieve. The main limitation of these models was the need to train the model on only a single type of data such as human faces, and the model would only be able to output an image in the said domain. But let’s stop at GAN-s for a second, a GAN in its original form takes random noise and produces an output in a single step which is a complex task for the model to learn and can lead to many difficulties in training and suboptimal outputs. We have explored the use of GAN-s in the past for removal of Windfarm clutter in Radar imagery with a good level of success.
The true revolution came in the form of multimodal models, models which combine multiple modalities. In this case I am referring to models such as DALL-E and its less known relative CLIP, where DALL-E could generate images grounded in a text prompt while CLIP would be used to order how good the generated images are in regard to the prompt. There were some shortcomings of DALL-E such as the compute required due to being Transformer based, but future work would refine the idea further, bringing us to Diffusion models.
Diffusion models work on a simple but powerful idea. It is hard to make something out of nothing, as alchemist have discovered through the ages. The problem is rephrasing as removing small amounts of noise iteratively. There is a bit more to it than that, but that is the main idea. The model is supplied with a random noise seed which it is progressively asked to remove (the model does not attempt to predict the image without the noise, but the noise itself and it is removed from the image), all the while being grounded with a text prompt. The idea can then be extended to videos, but more work is required in this area before we will be able to see AI generated blockbusters (https://makeavideo.studio/).
Could this technique be used in any way for hardware design? Previously we have employed AI techniques with success for task such as a heatsink design. Now the question would be could multimodal models in the future be used to produce designs from our specifications? The image bellow uses Stable Diffusion 2 (https://huggingface.co/spaces/stabilityai/stable-diffusion) for the prompt “A radar blueprint with 3 transmitter and 4 receiver antennas CAD model”.
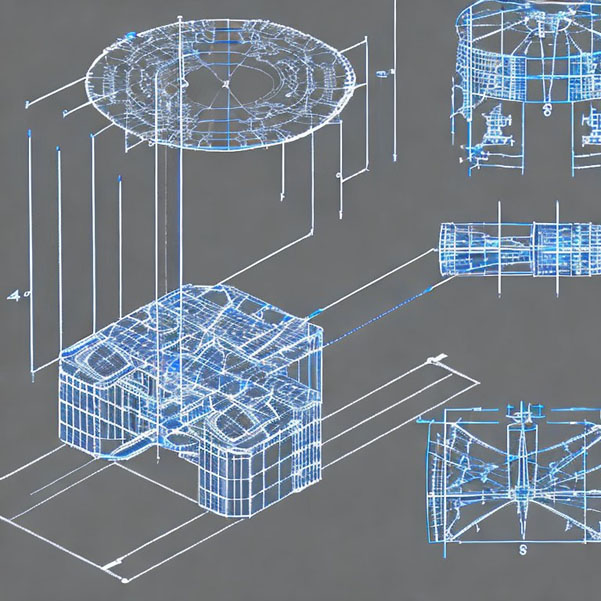
Could this prompt be improved with ChatGPT (https://openai.com/blog/chatgpt/)? If we ask ChatGPT to suggest a prompt which would result with a high-quality image for our previous prompt it recommends: “Generate a high-quality CAD model of a radar blueprint featuring 3 transmitter and 4 receiver antennas, rendered in accurate detail and clearly labelled.”

While visually impressive I still do not think we are there, yet! But I look forward to seeing what the future would bring. Now it is over to you. Do you see any potential in using such multimodal models? Would there be any benefits of using additional modalities such as audio/RF? Please let us know your opinions, and if we could use any of these techniques to help with some of your challenges?





